
Written by: Ashwin V. Mohanan
Introduction: Why secure coding matters in Data Science
In the fast-paced world of data science, security is often an afterthought. Deadlines, deliverables, and the pressure to build functional models can push security concerns to the back burner. Yet, integrating secure coding practices into your workflow is not just a necessity but an opportunity to build more robust, reliable, and resilient systems. As David Eklund, an AI researcher at RISE, points out, secure coding isn’t about becoming a cybersecurity expert overnight. It’s about increasing awareness, adopting new habits, and understanding how your code could be exploited. Even small steps can make a significant difference.
One practical way to begin is by exploring established frameworks like the Application Security Verification Standard (ASVS), developed by the Open Worldwide Application Security (OWASP) Foundation. ASVS provides a comprehensive set of security requirements tailored to various aspects of software development, which could be relevant for machine learning workflows and data pipelines. The standard is organized into 17 chapters, each addressing a specific area of security, from input validation to file handling. It offers three levels of security requirements: L1 (minimum security), L2 (standard security), and L3 (advanced security), ensuring scalability for projects of all sizes and complexities.
Understanding the ASVS Framework
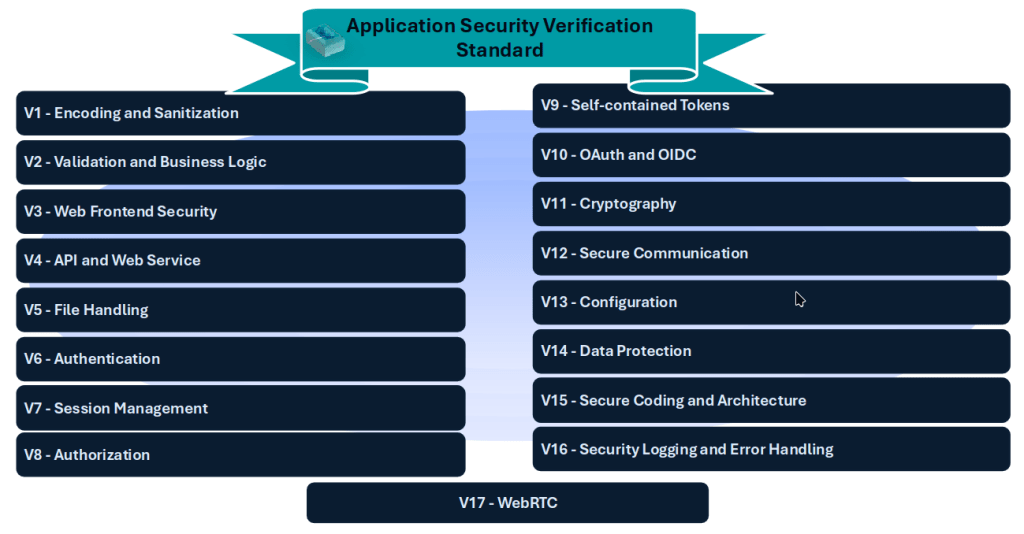
Application Security Verification Standard (ASVS)
The ASVS framework is designed to help developers and data scientists mitigate common vulnerabilities. For example, Chapter V5 focuses on file handling – a critical area for data scientists who frequently work with user-uploaded files. Improper file handling can lead to severe consequences, such as storage exhaustion, denial-of-service attacks, or unauthorized access to sensitive data. The standard outlines clear requirements, such as limiting file sizes, verifying file extensions, and ensuring the content matches the declared type. These measures are foundational for preventing exploits that could compromise your system.
But ASVS is just one piece of the puzzle. Abdul Ghafoor, a Cyber-security Specialist, emphasizes the importance of the shift-left approach. This philosophy advocates for integrating security early in the software development lifecycle (SDLC), rather than treating it as an afterthought. The goal is to identify and eliminate vulnerabilities as early as possible, reducing the risk of costly breaches later on.
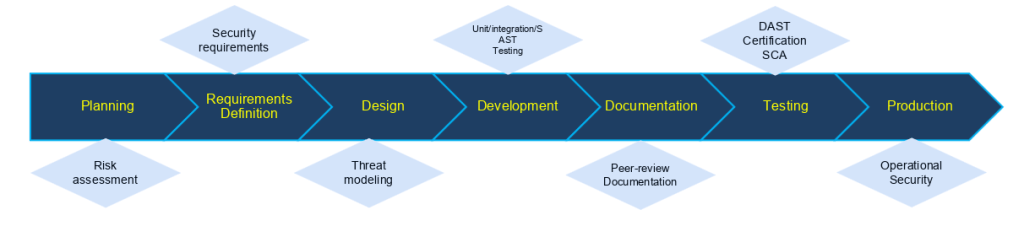
Shift-left approach: Proactively uncover unknown security issues within complex systems before they manifest into business-impacting problems
Shift-left doesn’t mean overburdening developers with security tasks. Instead, it’s about empowering teams with tools and awareness. Automated security tools, such as static and dynamic code analyzers, can be integrated into existing pipelines to streamline the process. By fostering a culture of security, organizations can ensure that every team member – from developers to data scientists – plays a role in building secure applications.
Core principles of secure coding
At the heart of secure coding are four fundamental principles:
- Principle of Least Privilege: Grant users the minimum access necessary to perform their tasks. This limits the potential damage if a system is compromised.
- Defense in Depth: Implement multiple layers of security to protect against a wide range of threats. This includes input validation, encoding, and access controls.
- Fail Securely: Design systems to handle failures gracefully. For instance, if an input causes an error, the system should not crash or expose sensitive information.
- Keep It Simple: Security controls should be intuitive and easy to use. Complexity can introduce new vulnerabilities, so simplicity is key.
These principles are especially relevant for data scientists, who often work with sensitive data and complex workflows. For example, encoding and sanitization (Chapter V1) are critical for protecting against injection attacks, such as SQL injection or cross-site scripting (XSS). Data should be validated and sanitized before processing, and encoding should be applied consistently across the application. In practice, this means that the “sender” application should encode at the end, the “receiver” application should decode at the early stage.
Abdul illustrates this with a practical example: a function that reads log files based on user input.
def search_logs_oscommands(
user_pattern: str,
logfile: str = "/var/log/app.log"
):
cmd = f"grep -i {user_pattern} {logfile}"
subprocess.run(cmd, shell=True, check=False, timeout=10)
return cmd # return the command string for demonstration/testing
search_logs_oscommands("; ls") # Leaks data, but not critical
search_logs_oscommands("; && rm -rf /") # ⚠️ Danger!
Without proper validation, an attacker could inject malicious commands (e.g., rm -rf /) to delete files or disrupt operations. By decoding and validating inputs early, developers can prevent such exploits.
Validation and business logic security
Input validation is a cornerstone of secure coding. Whether the data comes from a user, an API, or a file, it should never be trusted blindly. Validation should check both syntax (e.g., correct email format) and semantics (e.g., logical constraints like positive values for age). Failing to validate inputs can lead to crashes, data corruption, or even system takeovers. Here are some examples of other kinds of validation:
- Type-checking.
- Type conversion with error handling.
- Validation against schemas such as JSON or XML.
- Value within range for numerical input.
- When possible, a small list of allowed values and a list of suspicious patterns for input.
Consider a scenario where a data scientist builds a model that accepts user-provided training data. Without validation, malicious data could skew the model’s performance or introduce biases. Similarly, when sharing model outputs, sanitization ensures that sensitive or harmful content is not exposed to end users. This is particularly important in agentic environments, where the output of one model becomes the input for another. Sanitization prevents cascading failures and maintains data integrity.
Business logic security is another critical area. For example, if an application accepts numerical inputs, it should enforce reasonable bounds (e.g., height cannot be negative). Such checks might seem trivial, but they prevent edge cases that attackers could exploit. See Chapter V2 of the ASVS standard for more on this topic.
The role of logging and error handling
Logging is often overlooked, yet it is one of the most powerful tools for security and debugging. Effective logging captures critical events, such as authentication attempts, access control changes, and security-related actions (e.g., encryption or decryption). Log files should be protected, encrypted, and stored securely, as they contain valuable information about system behavior.
Error handling is equally important. Generic error messages should be shown to users, while detailed logs are reserved for developers and security analysts. This prevents attackers from gaining insights into system weaknesses. Abdul stresses that logs are not just for troubleshooting – they are a comprehensive record of your application’s behavior, essential for forensic analysis in the event of a breach.
Python developers can leverage built-in logging libraries to implement structured logging. See Chapter V16 of the ASVS standard for guidelines on logging.
Tools and automation for secure development
Automation is a game-changer for secure coding. Tools like Black (for code formatting), and Ruff (for both formatting and linting) help maintain consistency and catch common issues.
Abdul recommends integrating Static Application Security Testing (SAST) and Dynamic Application Security Testing (DAST) into CI/CD pipelines. SAST tools (for example, CodeQL, SonarQube) analyze source code for vulnerabilities, while DAST tools (for example, OWASP ZAP, Burp Suite, ACME) test running applications for runtime issues. Together, they provide a robust defense against both known and emerging threats.
For data scientists working in Python, tools like Bandit (for static code analysis of security issues) and pip-audit (for dependency checks) can further enhance security by identifying vulnerabilities early. For dependency management, Software Bill of Materials (SBOM) can be generated using pip-audit to ensure that only trusted libraries are used, reducing the risk of supply chain attacks. These tools make it easier to adhere to security best practices without slowing down development.
Conclusion: building a security-aware culture
Secure coding is not a one-time task – it’s a continuous process. By adopting frameworks like ASVS, embracing the shift-left approach, and leveraging automation, data scientists can build systems that are both powerful and secure. The key is to start small: validate inputs, sanitize outputs, and log critical events. Over time, these practices become second nature, leading to more resilient and trustworthy applications.
As David and Abdul demonstrate, security doesn’t have to be a burden. With the right mindset, tools, and habits, it can be an integral – and even enjoyable – part of the development process. After all, writing secure code isn’t just about protecting data; it’s about building software that users can trust.
Have questions or experiences to share? Join the conversation and let’s make secure coding a standard practice in data science!