
By: Abdul Ghafoor
Introduction
Recent findings reveal that 42% of companies abandoned most of their AI initiatives within a single year, citing security and privacy risks as more prohibitive than cost.
The cybersecurity requirements of AI models differ fundamentally from those of traditional software systems, which follow deterministic logic. AI models, however, learn from data, adapt over time, and often operate as black boxes. This behavior introduces new attack surfaces and risk vectors that conventional cybersecurity controls were never designed to handle. In such situations, relying on static security methods proves ineffective, as AI systems are dynamic, probabilistic, and continuously evolving.
Securing AI Models and Pipelines
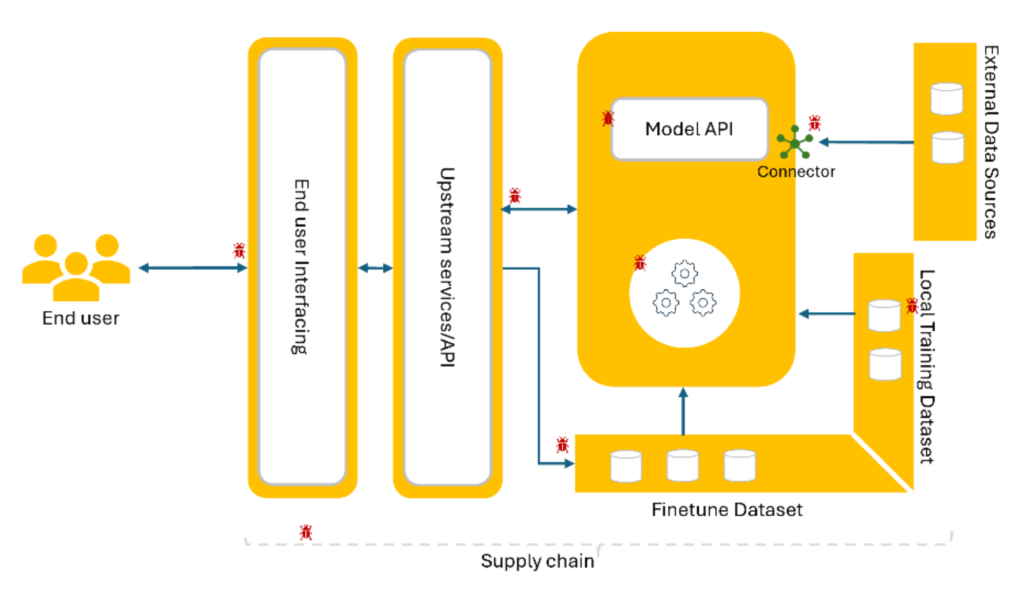
AI models and pipelines span multiple stages, including data ingestion, preprocessing and feature engineering, model training, evaluation, validation, and deployment within production applications. Due to their non-deterministic and data-driven nature, AI systems introduce attack surfaces that differ significantly from traditional deterministic software. These include threats such as training-time attacks (e.g., data poisoning and backdoor insertion), inference-time attacks (e.g., prompt injection and context-manipulation attacks), model integrity violations (e.g., model tampering and weight manipulation), and privacy-related attacks such as membership inference and model extraction.
The AI supply chain further expands the threat landscape through dependencies on third-party datasets, pretrained models, libraries, and model-hosting infrastructure, increasing the risk of compromise across the entire pipeline. When viewed through a security engineering lens, the AI model and pipeline can be systematically threat-modelled to identify control gaps and apply layered defenses, including data provenance validation, model integrity checks, runtime monitoring, and secure deployment controls. Adopting a holistic security architecture, grounded in secure-by-design, privacy-by-design, and intent-by-design principles, helps ensure that AI systems remain robust, trustworthy, and aligned with organizational risk tolerance and regulatory compliance requirements.
Common Attack Vectors Against AI Models
Data Poisoning Attack
Accurate prediction is highly dependent on the quality of data used for AI model training. In a data poisoning attack, an adversary injects malicious, corrupted, or biased samples into the training dataset to manipulate model behavior or cause it to learn incorrect patterns. The objective of such attacks is to degrade model accuracy, introduce systematic bias, or intentionally influence outputs, ultimately undermining the trustworthiness of the AI system. For example, poisoning medical training data could lead to incorrect disease diagnoses or unsafe clinical recommendations.
Adversarial attacks
Adversarial attacks occur when an attacker slightly perturbs or crafts inputs to deliberately cause incorrect predictions. These attacks are designed to deceive machine learning models by providing carefully manipulated inputs that lead to misclassifications or erroneous outputs. Adversarial techniques can also be used to extract sensitive or private data from models. The primary purpose of such attacks is to disrupt the behavior and reliability of machine learning systems. For example, altering a road sign could mislead an autonomous vehicle, causing traffic hazards, or subtle modifications to medical data could result in incorrect diagnoses.
Model Inversion and Data Extraction Attack
In this attack, the attacker can exploit model outputs to infer sensitive information about the training data, even without direct access to the dataset. The prompts are engineered for these specific purposes, and the attacker must have the knowledge of the AI model. The main purpose of such attack in the exposure of personal or confidential data which leads to the regulatory compliance violations (e.g., GDPR). For example, reconstructing patient data from a healthcare prediction model.
Supply Chain Attacks
AI systems and pipelines heavily rely on third-party libraries, pretrained models, and external datasets. A compromise at any point in the supply chain can propagate downstream and affect dependent systems. The purpose of such attacks is often to introduce hidden backdoors, enabling unauthorized access to an organization’s infrastructure and potentially causing widespread compromise. For example, a medical AI system that uses a third-party library could be targeted by a malicious update containing hidden code, which exfiltrates patient health data to an external server.
For readers interested in a deeper understanding of AI attacks and vulnerabilities, we recommend consulting OWASP, which provides comprehensive guidelines and threat frameworks such as the Machine Learning Security Top 10 and the Top 10 for Large Language Model Applications, offering detailed insights into common attack vectors, model risks, and mitigation strategies for AI systems.
Protection Measures for AI Models and Pipelines
Effective AI cybersecurity requires a holistic, lifecycle-based approach, addressing risks across data collection, model training, deployment, and monitoring stages.
Adopt Shift-Left Approach
The shift-left approach in the development of AI-based systems emphasizes identifying vulnerabilities as early as possible, which reduces downstream risks and optimizes resource usage. By integrating security practices into the initial stages of the AI lifecycle, organizations can proactively mitigate threats before models are deployed. Recommended practices include performing threat modelling and risk assessments during model design, implementing required security controls early in the pipeline, and using automated tools for vulnerability scanning of both AI models and associated code. Additionally, incorporating security checks into CI/CD workflows, validating third-party dependencies, and testing for data and model integrity during training further strengthens the AI pipeline. This proactive strategy ensures that security is built into AI systems from the ground up, rather than addressed reactively after deployment.
Protection of Training Data
Protecting training data is a critical component of AI cybersecurity and requires a comprehensive data management plan. Effective measures include validating and sanitizing datasets to prevent malicious or anomalous inputs, maintaining detailed data provenance to ensure traceability and trust, and enforcing data integrity and confidentiality through hashing, checksums, and encryption. Equally important is implementing strict access control and authorization mechanisms, such as role-based access control (RBAC), to ensure that only authorized personnel or systems can modify or access training data. Together, these practices help mitigate the risk of data poisoning and other training-time attacks, safeguarding the reliability, security, and trustworthiness of AI models.
Model Hardening and Validation
AI models are designed to generate outputs, but limiting the granularity of these outputs can provide better protection against data or model extraction attacks. This strategy can also help mitigate privacy risks. In scenarios where highly sensitive data is used, it is recommended to apply differential privacy techniques to ensure that individual data points cannot be inferred from model outputs.
Most traditional security measures help protect against supply chain attacks, but AI systems introduce additional risks due to their reliance on third-party libraries, pretrained models, and external datasets. To mitigate these risks, organizations should implement multiple controls before deployment: performing static and dynamic source code analysis, conducting software composition analysis, and restricting dependencies to trusted Software Bills of Materials (SBoMs). In addition, validating the provenance and integrity of pretrained models, signing and verifying third-party packages, and continuously monitoring dependencies for vulnerabilities are essential practices. These measures collectively reduce the likelihood of malicious code or hidden backdoors entering the AI pipeline and help maintain the trustworthiness and security of deployed AI systems.
Adversarial training
To enhance a model’s resilience against adversarial attacks, adversarial training is recommended. This approach involves intentionally introducing carefully crafted perturbations into input data designed to mislead the model and induce incorrect predictions. By incorporating these adversarial examples during training, the model learns to handle worst-case scenarios, thereby reducing its sensitivity to real-world adversarial manipulations and improving overall robustness.
Continuous Monitoring and Response
To ensure the reliability and security of AI systems, organizations must actively monitor and manage their models throughout their lifecycle. Detecting model drift and unusual behavior early helps identify performance degradation or potential threats before they cause significant impact. When issues arise, teams should be prepared to retrain models with updated data or roll back compromised versions to restore trusted performance quickly. Maintaining incident response plans tailored specifically to AI systems ensures faster, more effective action during failures or attacks. Additionally, auditing logs and monitoring for malicious events provide critical visibility into system activity, enabling organizations to trace issues, strengthen defenses, and maintain ongoing trust in their AI solutions.
Conclusion
AI systems bring transformative potential, but they also introduce unique security risks across data, models, and pipelines. From data poisoning and adversarial attacks to supply chain threats, organizations must adopt a holistic, proactive approach—protecting training data, hardening models, testing iteratively, securing dependencies, and shifting security left in the development process. By embedding security throughout the AI lifecycle, teams can ensure their systems remain reliable, trustworthy, and resilient in the face of evolving threats.